

کارتهای گرافیک NVIDIA (GPU) دستگاههای قدرتمندی هستند که میتوانند همزمان صدها تا هزاران محاسبه را با استفاده از هستههای پردازشی متعدد انجام دهند. با معرفی ریزمعماری Hopper در سال 2022، کارت NVIDIA H100 به یکی از قدرتمندترین کامپیوترهای تکی تبدیل شده که تاکنون برای مصرفکنندگان عرضه شده و عملکردی بسیار بهتری از نسل قبلی (Ampere) دارد.
در هر نسل جدید از ریزمعماری (که به نوعی زبان دستورالعملهای پردازنده محسوب میشود)، NVIDIA بهبودهای قابلتوجهی در ظرفیت حافظه گرافیکی (VRAM)، تعداد هستههای CUDA و پهنای باند نسبت به نسل قبل ایجاد کرده است. در حالی که کارتهای قدرتمند Ampere، بهویژه مدل A100، در پنج سال گذشته آغازگر موج جدیدی در زمینه هوش مصنوعی بودند، کارتهای نسل Hopper با سرعتی بیسابقه این روند پیشرفت را ادامه دادهاند.
در این مقاله، به بررسی و مرور برخی از پیشرفتهای چشمگیر در جدیدترین و قدرتمندترین کارت گرافیک مخصوص دیتاسنتر شرکت NVIDIA، یعنی سری Hopper H100، خواهیم پرداخت.
نگاهی به نمای کلی NVIDIA H100
کارت گرافیک NVIDIA H100 Tensor Core نسبت به مدل قبلی خود یعنی A100، در چندین زمینه کلیدی یک گام رو به جلو محسوب میشود. در این بخش، برخی از این پیشرفتها را با تمرکز بر کاربردهای آن در حوزه Deep Learning بررسی خواهیم کرد. این بهبودها باعث شدهاند H100 در آموزش و اجرای مدلهای پیچیدهتر عملکرد بسیار بالاتری ارائه دهد.
برای شروع، کارت گرافیک H100 در رتبه دوم از بیشترین پهنای باند حافظه در میان کارتهای PCIe در بین تمام GPUهای تجاری موجود قرار دارد. (رتبه اول متعلق به مدل جدیدتر یعنی H200 است). با پهنای باندی بیش از ۲ ترابایت بر ثانیه، این مدل قادر است بزرگترین مجموعه دادهها و مدلها را با استفاده از ۸۰ گیگابایت حافظهی VRAM با سرعتی بسیار بالا بارگذاری و پردازش کند. این ویژگی باعث میشود کارت گرافیک NVIDIA H100 عملکردی استثنایی، بهویژه در کاربردهای هوش مصنوعی در مقیاس وسیع، از خود نشان دهد.
این توان عبور فوقالعاده از دادهها، بهواسطهی نسل چهارم هستههای Tensor در H100 فراهم شده است؛ هستههایی که نسبت به نسلهای پیشین پردازندههای گرافیکی، جهشی چشمگیر بهشمار میآیند. H100 دارای ۶۴۰ هستهی Tensor و ۱۲۸ هستهی Ray Tracing است که پردازش دادهها با سرعت بالا را ممکن میسازند. این ساختار، در کنار ۱۴٬۵۹۲ هستهی CUDA، باعث میشود توان پردازشی در محاسبات با دقت کامل (fp64) به رقم قابل توجه ۲۶ ترافلاپس برسد.
علاوه بر این، فناوری هستههای Tensor در NVIDIA H100 از دامنهی گستردهای از دقتهای محاسباتی پشتیبانی میکند و یک شتابدهندهی واحد را برای تمامی بارهای کاری محاسباتی فراهم میآورد. کارت H100 با رابط PCIe قادر است وظایف محاسباتی با دقت مضاعف (FP64)، دقت یکنواخت (FP32)، دقت نیمه (FP16) و مقادیر صحیح (INT8) را پشتیبانی نماید.

ویژگیهای جدید در پردازندههای گرافیکی Hopper
در ریزمعماری Hopper، ارتقاءهای چشمگیری اعمال شده است؛ از جمله بهبود فناوری هستههای Tensor، معرفی موتور Transformation و بسیاری قابلیتهای دیگر. در ادامه، به بررسی دقیقتر برخی از مهمترین این ارتقاءها خواهیم پرداخت.
هستههای Tensor نسل چهارم همراه با موتور Transformer
بدون شک یکی از مهمترین بهروزرسانیها برای کاربران حوزه یادگیری عمیق (Deep Learning) یا هوش مصنوعی، معرفی نسل چهارم هستههای Tensor است که افزایش عملکردی تا ۶۰ برابر نسبت به نسخهی قبلی در معماری Ampere را وعده میدهد. برای دستیابی به این سطح از شتابدهی، شرکت NVIDIA موتور جدیدی بهنام Transformer Engine ارائه کرده است. این موتور، بخش اصلی هر هسته Tensor به شمار میرود و بهطور خاص برای تسریع مدلهایی طراحی شده که بر پایهی ساختار Transformer ساخته شدهاند. با بهرهگیری از این فناوری، عملیات محاسباتی بهصورت پویا در قالبهای ترکیبی FP8 و FP16 انجام میشود.
از آنجا که نرخ عملیات شناور (FLOPs) در قالب FP8 در هستههای Tensor دو برابر FP16 است، اجرای مدلهای یادگیری عمیق در این قالبها از نظر هزینه بسیار بهصرفهتر خواهد بود. با این حال، استفاده از FP8 میتواند دقت مدل را بهطور چشمگیری کاهش دهد. نوآوری Transformer Engine این امکان را فراهم کرده است تا در عین بهرهبردن از افزایش پهنای باند قالب FP16، کاهش دقت ناشی از استفاده از FP8 نیز جبران شود. این امر از طریق تغییر پویا بین قالبهای عددی در هر لایه از مدل انجام میشود، به این معنا که بسته به نیاز، موتور میتواند بهطور خودکار بین FP8 و FP16 جابهجا شود.
علاوه بر این، معماری Hopper شرکت NVIDIA بهطور خاص، هستههای Tensor نسل چهارم را تا سه برابر نسبت به نسل قبلی در قالبهای TF32، FP64، FP16 و INT8 از نظر تعداد عملیات ممیز شناور در ثانیه (FLOPs) بهبود داده است.
MIG امن نسل دوم
ویژگی MIG یا Multi-Instance GPU در نسل دوم خود در معماری Hopper بهبود چشمگیری یافته است. MIG به کاربران این امکان را میدهد که یک GPU واحد مانند NVIDIA H100 را به چندین نمونه مستقل تقسیم کنند که هرکدام منابع اختصاصی خود (از جمله حافظه، کش و پهنای باند) را داشته باشند.
در نسخهی دوم MIG، امنیت و ایزولهسازی بین نمونهها تقویت شده است، بهطوریکه هر نمونه میتواند بهصورت کاملاً مستقل و امن اجرا شود، بدون اینکه فعالیتهای آن تأثیری بر دیگر نمونهها بگذارد. این ویژگی برای کاربردهای ابری، دیتاسنترها و محیطهایی که چندین کاربر بهطور همزمان به یک GPU دسترسی دارند، بسیار حیاتی است.
MIG امن نسل دوم، با بهرهگیری از مکانیزمهای امنیتی سختافزاری و نرمافزاری، نهتنها عملکرد بالا را تضمین میکند، بلکه از حملات جانبی (Side-channel attacks) و دسترسی غیرمجاز به دادهها نیز جلوگیری مینماید.
MIG یا Multi-Instance GPU، فناوریای است که امکان تقسیم یک GPU فیزیکی به چند نمونهی کاملاً مستقل و ایزولهشده را فراهم میسازد؛ بهطوری که هر نمونه، حافظه، کش و هستههای پردازشی اختصاصی خود را دارد.
در کارتهای H100، نسل دوم این فناوری ارتقاء یافته و این امکان را میدهد که GPU به حداکثر هفت نمونهی امن تقسیم شود. این قابلیت، پشتیبانی از چند کاربر و چند مستأجر (multi-user / multi-tenant) را در محیطهای مجازی فراهم میکند، بدون آنکه تداخلی میان منابع پردازشی یا دادههای کاربران مختلف ایجاد شود.
در عمل، این ویژگی امکان به اشتراکگذاری GPU با سطح بالایی از امنیت داخلی را فراهم میسازد و یکی از عوامل کلیدی در محبوبیت H100 برای کاربران فضای ابری بهشمار میرود.
هرکدام از نمونههای مستقل (MIG Instances) دارای رمزگشای ویدیویی اختصاصی هستند که وظیفه ارائه تحلیلهای هوشمند ویدیویی (Intelligent Video Analytics – IVA) از زیرساخت مشترک را مستقیماً به سامانههای نظارتی برعهده دارند. همچنین، مدیران شبکه میتوانند با استفاده از قابلیت Concurrent MIG Profiling در معماری Hopper، وضعیت استفاده از منابع را بهصورت لحظهای رصد کرده و تخصیص آنها را بهینهسازی کنند.
NVLink نسل چهارم و NVSwitch نسل سوم
NVLink و NVSwitch از جمله فناوریهای شرکت NVIDIA هستند که امکان اتصال چندین پردازنده گرافیکی (GPU) را در یک سیستم یکپارچه فراهم میکنند. با هر نسل جدید، این فناوریها بهبود چشمگیری یافتهاند. NVLink یک سختافزار ارتباطی دوطرفه است که به GPUها اجازه میدهد دادهها را با یکدیگر به اشتراک بگذارند، در حالی که NVSwitch تراشهای است که ارتباط بین دستگاههای مختلف را در یک سیستم چند GPU با اتصال رابطهای NVLink به GPUها تسهیل میکند.
در پردازندههای H100، نسل چهارم NVLink بهطور مؤثری تعاملات ورودی/خروجی چندنمونهای GPU را تا نرخ ۹۰۰ گیگابایت بر ثانیه (GB/s) بهصورت دوطرفه برای هر GPU افزایش میدهد که این میزان، بیش از ۷ برابر پهنای باند PCIe نسل پنجم (Gen5) تخمین زده میشود. این بدان معناست که GPUها میتوانند دادهها را با سرعتی بسیار بالاتر نسبت به نسل Ampere با یکدیگر مبادله کنند و همین نوآوری یکی از عوامل اصلی افزایش چشمگیر سرعت در سیستمهای چند GPU مبتنی بر H100 بهشمار میرود که در مطالب تبلیغاتی نیز بر آن تأکید شده است.
در مرحله بعد، نسل سوم NVSwitch شرکت NVIDIA از فناوری محاسباتی درونشبکهای تحت عنوان SHARP (پروتکل تجمیع و کاهش سلسلهمراتبی مقیاسپذیر) پشتیبانی میکند و موجب افزایش ۲ برابری نرخ all-reduce در میان هشت سرور GPU H100 نسبت به سیستمهای نسل قبل مبتنی بر A100 میشود. بهطور عملی، این موضوع بدان معناست که نسل جدید NVSwitch میتواند با کارایی و اثربخشی بالاتری عملیات موجود در سیستم چند-GPU را مدیریت کرده، منابع را بهدرستی تخصیص دهد و در سیستمهای DGX به شکل قابلتوجهی نرخ انتقال داده را افزایش دهد.
محاسبات محرمانه (Confidential Computing)
یکی از نگرانیهای رایج در عصر کلانداده (Big Data)، امنیت اطلاعات در هنگام پردازش آنهاست. در حالی که دادهها اغلب بهصورت رمزگذاریشده ذخیره یا منتقل میشوند، این روشها نمیتوانند از اطلاعات در برابر تهدیداتی که در حین پردازش رخ میدهند، محافظت کنند.
با معرفی ریزمعماری Hopper، شرکت NVIDIA راهکاری نوین برای این مشکل ارائه داد: محاسبات محرمانه (Confidential Computing). این فناوری با ایجاد فضایی فیزیکی و ایزولهشده برای پردازش دادهها، محیطی امن به نام «محیط اجرای مورد اعتماد» (Trusted Execution Environment یا TEE) فراهم میکند که بارهای کاری را مستقل از سایر اجزای سیستم اجرا مینماید. این جداسازی باعث میشود دسترسی به دادههای محافظتشده برای مهاجمان بسیار دشوارتر شود، زیرا کل فرآیند پردازش در محیطی انجام میگیرد که حتی سیستمعامل و مدیران زیرساخت نیز به آن دسترسی ندارند.

مقایسه NVIDIA H100 و A100
کارت گرافیک NVIDIA H100 در تمامی جنبهها گامی چشمگیر به جلو نسبت به نسل پیشین خود، یعنی A100، محسوب میشود. این پیشرفتها تنها به فناوریهای جدیدی که پیشتر به آنها اشاره شد محدود نمیشوند، بلکه شامل بهبودهای کمی قابل توجهی در قدرت پردازشی هستند که یک دستگاه منفرد قادر به ارائه آن است. این یعنی H100 نهتنها از نظر فناوریهای نوین پیشرو است، بلکه از لحاظ توان خام پردازشی نیز بهمراتب قدرتمندتر عمل میکند.
این جدول، مقایسهای دقیق و کامل از دو کارت گرافیک قدرتمند NVIDIA A100 و NVIDIA H100 PCIe را نشان میدهد. هر دو کارت در کاربردهای هوش مصنوعی و پردازشهای سنگین بسیار مورد استفاده قرار میگیرند.
| NVIDIA H100 PCIe | NVIDIA A100 | ویژگیهای GPU |
| NVIDIA Hopper | NVIDIA Ampere | معماری GPU |
| PCIe Gen 5 | SXM4 | فرم فکتور برد GPU |
| 114 | 108 | تعداد SM ها |
| 57 | 54 | تعداد TPC ها |
| 128 | 64 | /FP32 هستههای هر SM |
| 14592 | 6912 | /FP32 هستههای کل GPU |
| 64 | 32 | /FP64 هستههای هر SM(Tensor بدون) |
| 7296 | 3456 | /FP64 هستههای کل GPU(Tensor بدون) |
| 64 | 64 | /INT32 هستههای هر SM |
| 7296 | 6912 | / INT32 هستههای کل GPU |
| 4 | 4 | /Tensor هستههای هر SM |
| 456 | 432 | / Tensor هستههای کل GPU |
| نهایی نشده | 1410 مگاهرتز | GPU فرکانس بوست |
| 1600 / 32002 | ناموجود | FP8 با تجمع قدرت پردازشی FP16 (TFLOPS) |
| 1600 / 32002 | ناموجود | FP8 با تجمع قدرت پردازشی FP32 (TFLOPS) |
| 8002/400 | 156/3122 | بیشینه توان محاسباتی TFLOPS1 TF32 Tensor |
| 48 | 19.5 | بیشینه توان محاسباتی TFLOPS1 FP64 Tensor |
| 1600/32002 | 624/12482 | بیشینه توان عملیاتی تانسور INT8 به واحد TOPS |
| 96 | 78 | بیشینه توان محاسباتی FP16 به واحد TFLOPS (non-Tensor)1 |
| 96 | 39 | بیشینه توان محاسباتی BF16 به واحد TFLOPS (non-Tensor)1 |
| 48 | 19.5 | بیشینه توان محاسباتی FP32 به واحد TFLOPS (non-Tensor)1 |
| 24 | 9.7 | بیشینه توان محاسباتی FP64 به واحد TFLOPS (non-Tensor)1 |
| 80 گیگابایت | 40 یا 80 گیگابایت | سایز مموری |
| 2000 GB/sec | 1555 GB/sec | پهنای باند حافظه |
ابتدا، همانطور که از جدول بالا مشخص است، کارت گرافیک H100 تعداد کمی بیشتری چندپردازنده جریانی (Streaming Multiprocessors یا SM) و مرکزهای پردازش بافت (Texture Processing Centers یا TPC) نسبت به A100 دارد، اما تعداد هستههای Tensor آن برای هر فرمت عددی محاسباتی و در هر SM بهطور قابل توجهی بیشتر است.
در واقع، H100 دو برابر تعداد هستههای FP32 در هر SM نسبت به A100 دارد، بیش از دو برابر هستههای FP64 در هر SM، حدود ۳۰۰ هسته INT32 بیشتر و ۲۴ هستهی Tensor اضافهتر نسبت به A100 دارد.
در عمل، این افزایشها بهطور مستقیم منجر به این میشود که هر واحد پردازشی در H100 بهتنهایی بسیار قدرتمندتر از واحدهای متناظر در A100 باشد.
کاملاً مشخص است که این موضوع بهصورت مستقیم بر شاخصهایی که با سرعت پردازش در ارتباط هستند تأثیر میگذارد؛ یعنی بیشینه عملکردها در فرمتهای عددی مختلف و همچنین پهنای باند حافظه.
در هر شرایط و کاربردی، H100 عملکرد بهتری نسبت به A100 دارد. افزون بر این، گسترش قابلیتها به FP8 همراه با انباشتهسازی گرادیان با دقت FP16 یا FP32 از طریق موتور Transformer، این امکان را فراهم میکند که محاسبات با دقت ترکیبی انجام شود؛ محاسباتی که A100 از عهدهی آنها برنمیآید.
این پیشرفت، بهصورت مستقیم منجر به افزایشی نزدیک به ۴۵۰ گیگابایت بر ثانیه در پهنای باند حافظه شده است؛ معیاری که حجم داده قابل انتقال در هر ثانیه را در سیستم نشان میدهد.
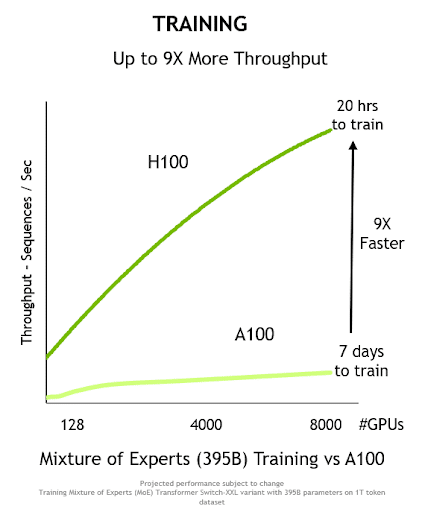
در چارچوب آموزش مدلهای زبانی بزرگ (Large Language Models)، این بهبودهای تجمعی در H100 باعث میشود که تا ۹ برابر سرعت بیشتر در فرآیند آموزش و ۳۰ برابر افزایش در توان پردازشی مرحلهی استنتاج (Inference) گزارش شود.
چه زمانی از NVIDIA H100 استفاده کنیم؟
همانطور که در این بررسی از H100 نشان دادیم، H100 گامی رو به جلو در تمامی ابعاد برای کارتهای گرافیک NVIDIA بهشمار میرود.
در هر سناریوی استفاده، عملکردی بهتر از بهترین کارت نسل قبلی یعنی A100 ارائه میدهد، آن هم با افزایش نسبتاً ناچیز در مصرف انرژی. همچنین توانایی کار با انواع مختلفی از فرمتهای عددی در حالت دقت ترکیبی (Mixed Precision) را دارد که موجب افزایش چشمگیر عملکرد میشود.
این پیشرفتها هم از طریق فناوریهای نوآورانه در معماری Hopper، هم از طریق بهبودهای ایجادشده در فناوریهای موجود، و نیز افزایش کلی در تعداد واحدهای محاسباتی در این کارت کاملاً قابل مشاهده است.
H100 در حال حاضر در اوج قدرت پردازندههای گرافیکی قرار دارد و برای طیف وسیعی از کاربردها طراحی شده است. این کارت گرافیک دارای عملکردی فوقالعاده قدرتمند است و بهشدت برای افرادی توصیه میشود که قصد دارند به آموزش مدلهای هوش مصنوعی بپردازند یا کارهایی انجام دهند که به توان پردازشی بالای GPU نیاز دارند.
سخن آخر
H100 در حال حاضر استاندارد طلایی در دنیای GPUهاست. اگرچه نسل جدید کارتهای گرافیک NVIDIA با نام Blackwell بهزودی بهصورت گسترده وارد فضای ابری خواهند شد، اما H100 و برادر پرقدرتترش H200 همچنان بهترین گزینههای موجود برای هر نوع وظیفهی یادگیری عمیق (Deep Learning) هستند.
نکته: این مقاله در زمانی نوشته شده است که کارت گرافیکهای سری Blackwell معرفی نشده بودند.
برای آشنایی بیشتر با این کارت گرافیک کافیست به وبسایت آداک فن آوری مانیا و صفحه محصول کارت گرافیک NVIDIA H100 مراجعه کنید.



